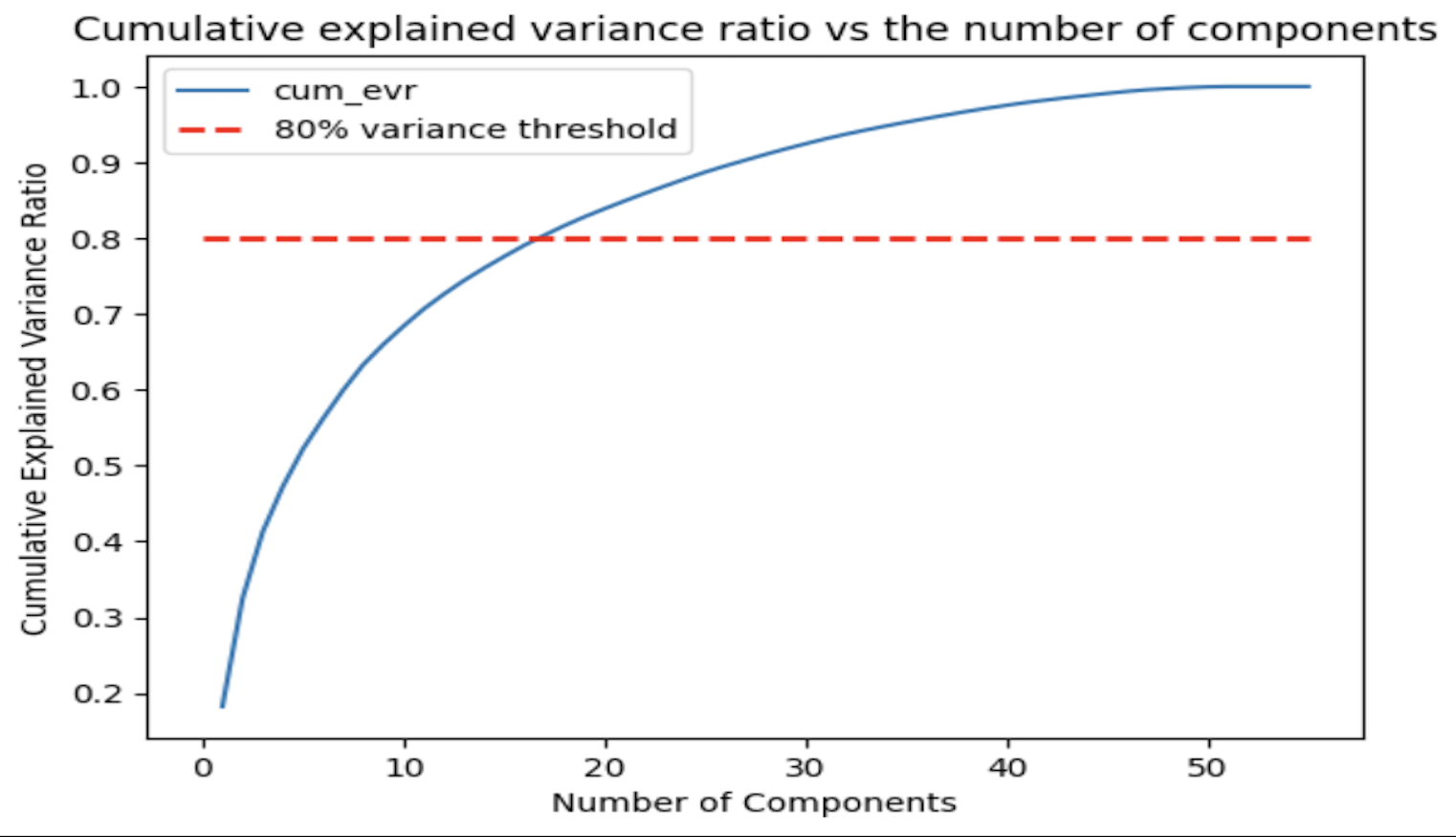
Big Data Analytics Project, Penn Engineering
Predicted Heart Disease Mortality by Zip Code using Logistic Regression and Random Forests; with the aid of PCA and Regularization methods.
Learn more
I am passionate researcher specializing in economics, finance, and data science. I hold a B.S. in Economics from the University of Oregon. And I am currently pursuing an M.S.E. in Data Science from UPenn, specializing in AI, Machine Learning, and Big Data
As a Research Analyst at The Wharton School, I develop finance algorithms, conduct data analysis on big data, and optimize models using languages such as R, Python, and SQL.
Through my previous internships at MIT and Princeton, I have gained expertise in text mining, NLP, and Causal Inference models for research. With my strong skill set and dedication, I am poised to make meaningful contributions to the field of Economics, Household Finance, and Machine Learning.
Linkedin
Predicted Heart Disease Mortality by Zip Code using Logistic Regression and Random Forests; with the aid of PCA and Regularization methods.
Learn more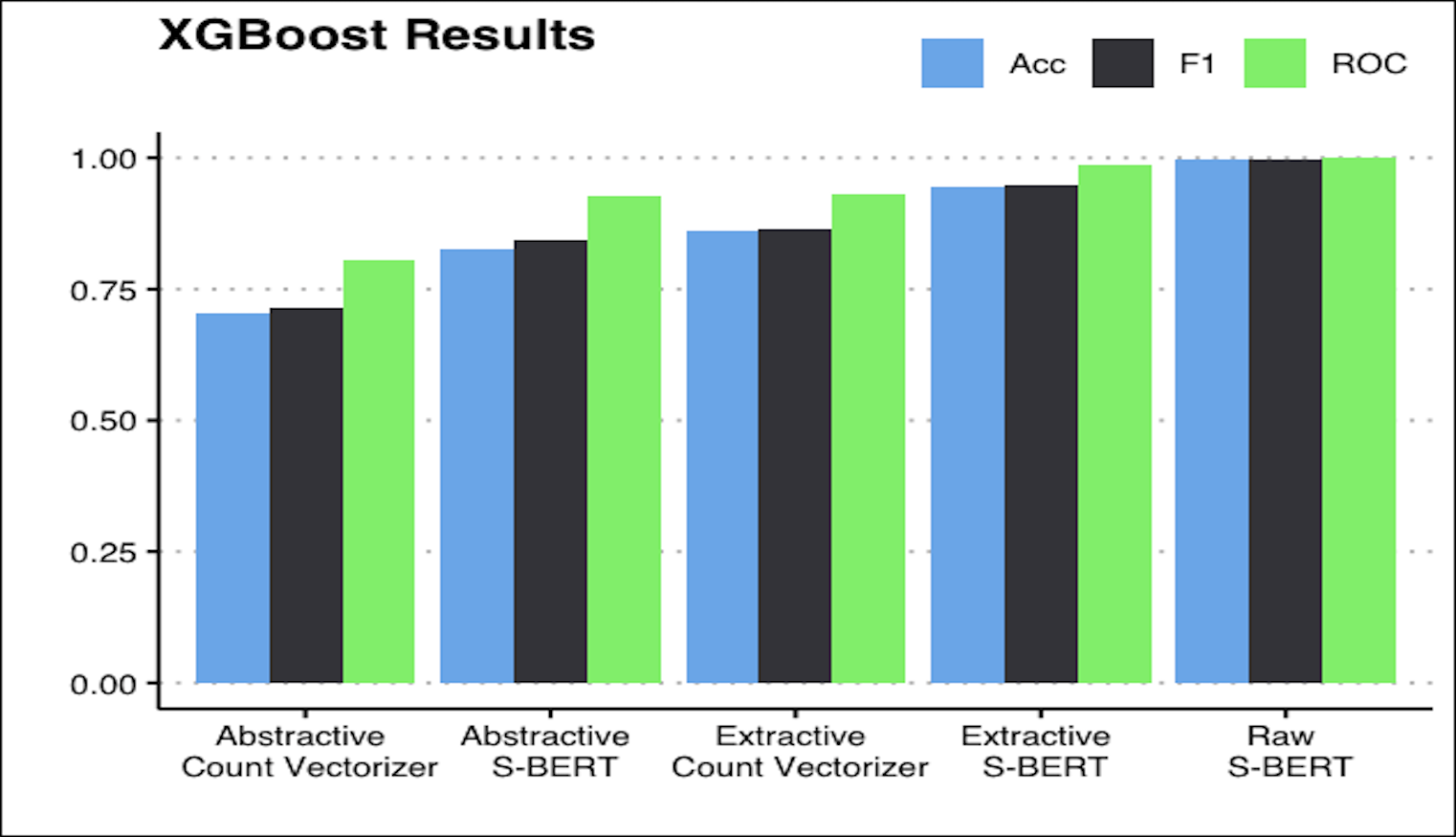
Investigated whether classification algorithms suffer a decrease in performance when classifying text summaries as opposed to the original text.
Learn more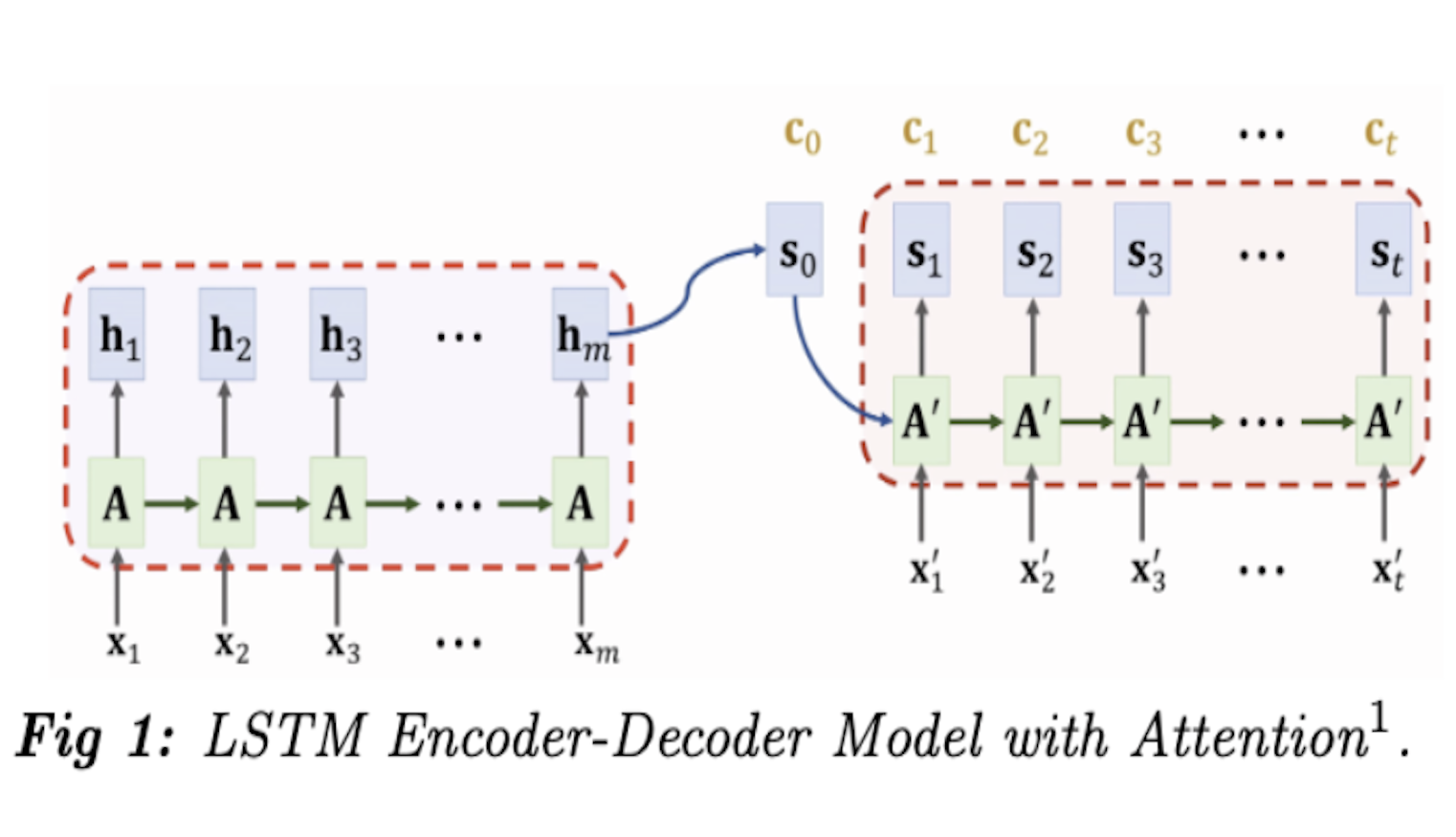
Implemented a Seq2Seq Model for Semantic Parsing using a Long Short-Term Memory (with and without Attention).
Learn more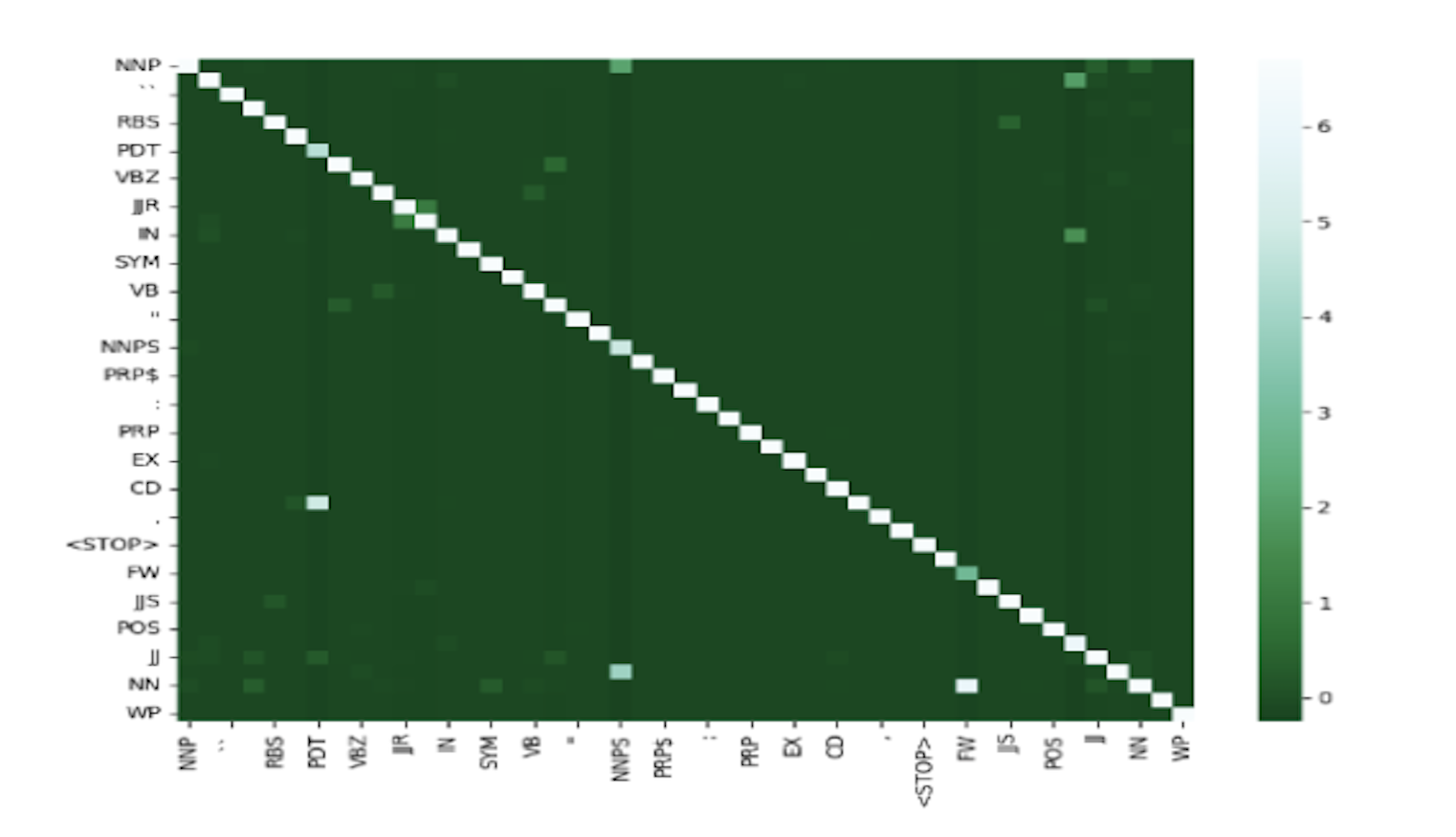
Incorporated Part-of-Speech Tagging using Hidden Markov and Maximum Entropy Models; e.g., Beam-k Search, Viterbi, and Greedy Classifiers.
Learn more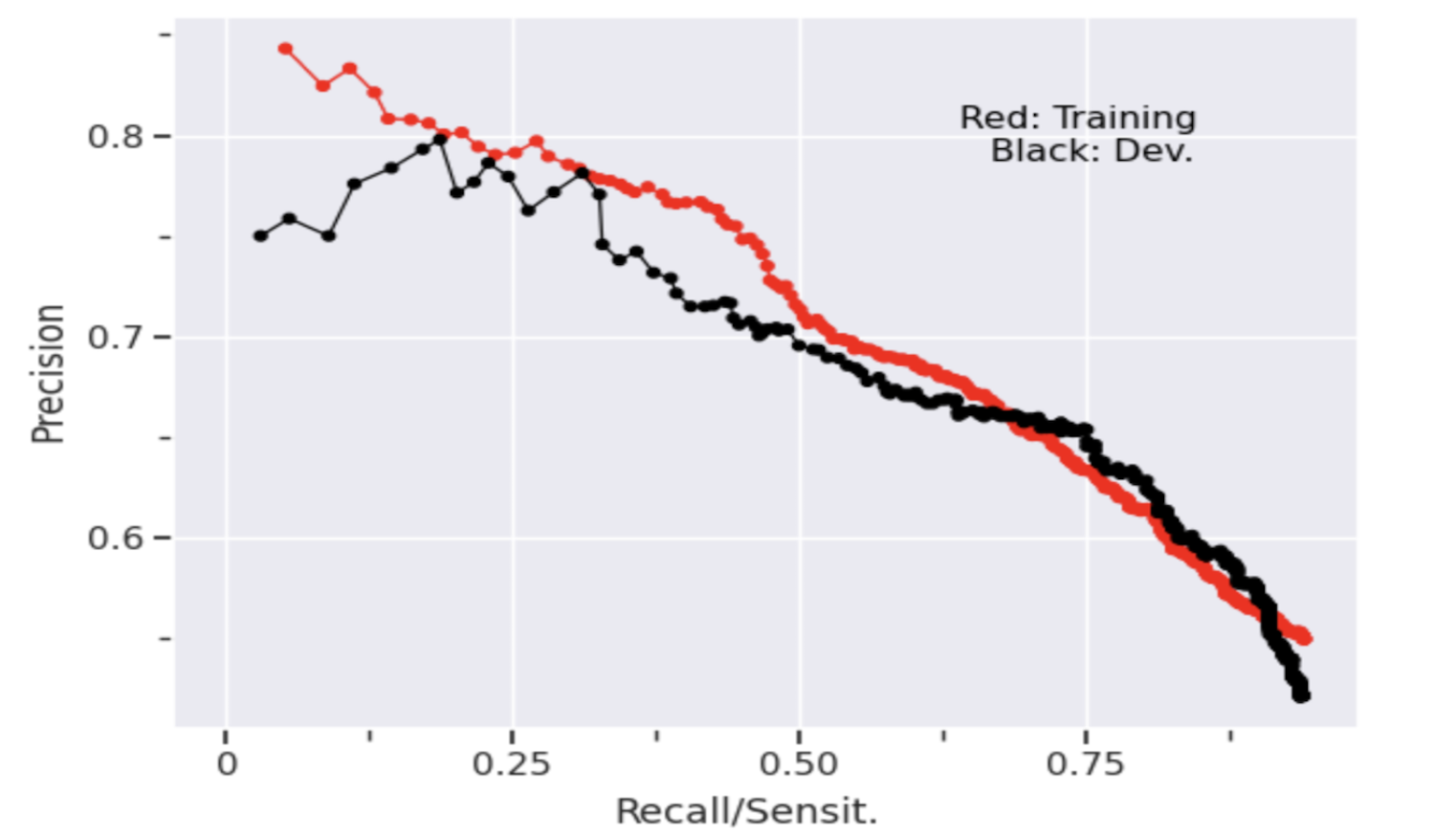
Used Adaboost, Naive Bayes, Logistic Regression, and Simple Baseline Classifiers to identify and categorize words that are "complex."
Learn more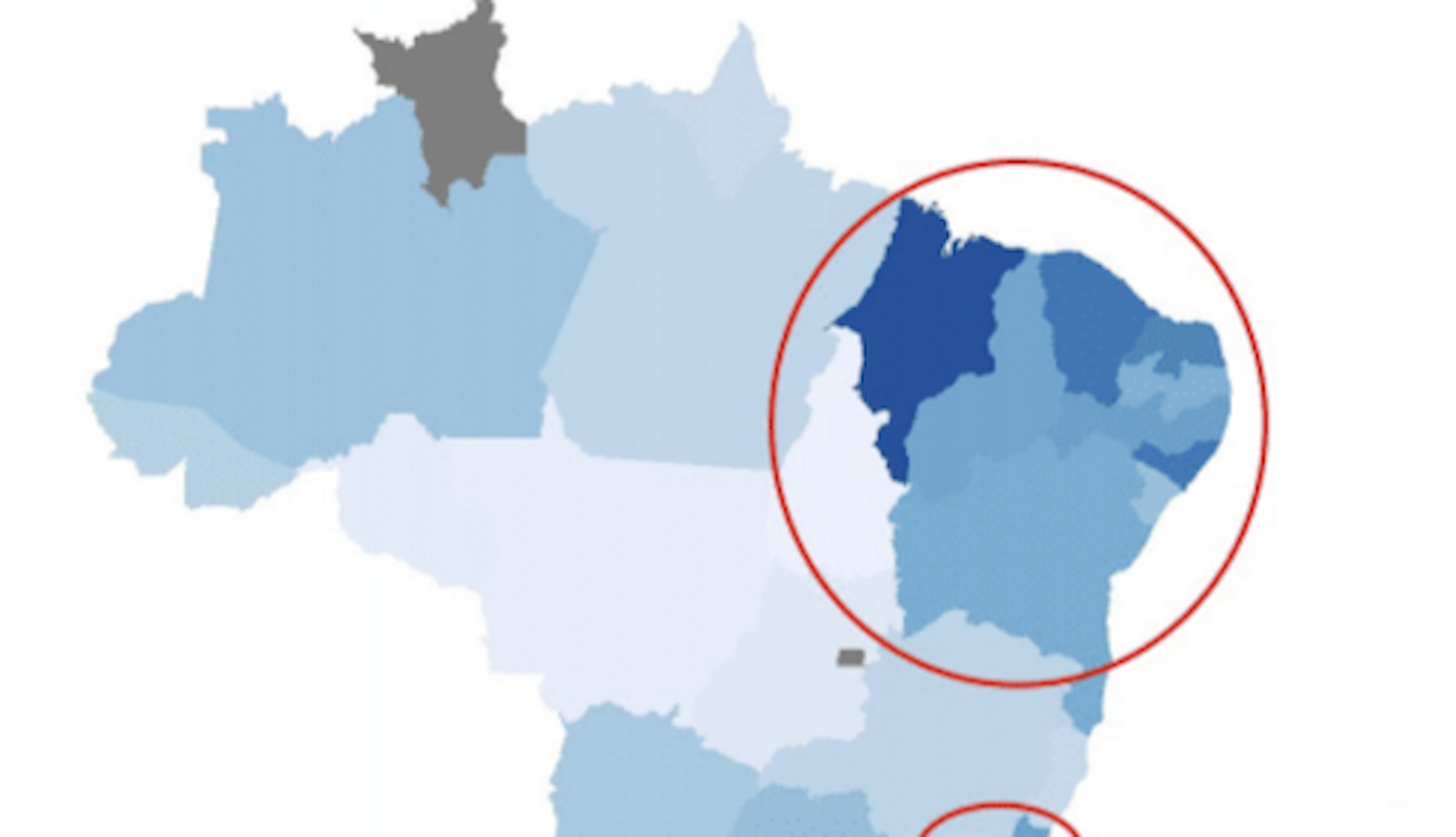
Used RegEx, Cloud Computing, OCR, NLP techniques to scan and webscrape over 120,000 PDF documents.
Learn more
Learned and worked with applied IVs, Regression Discontinuities, Diff-in-Diff, KNN, K-Means, and Machine Learning in a public policy context.
Learn more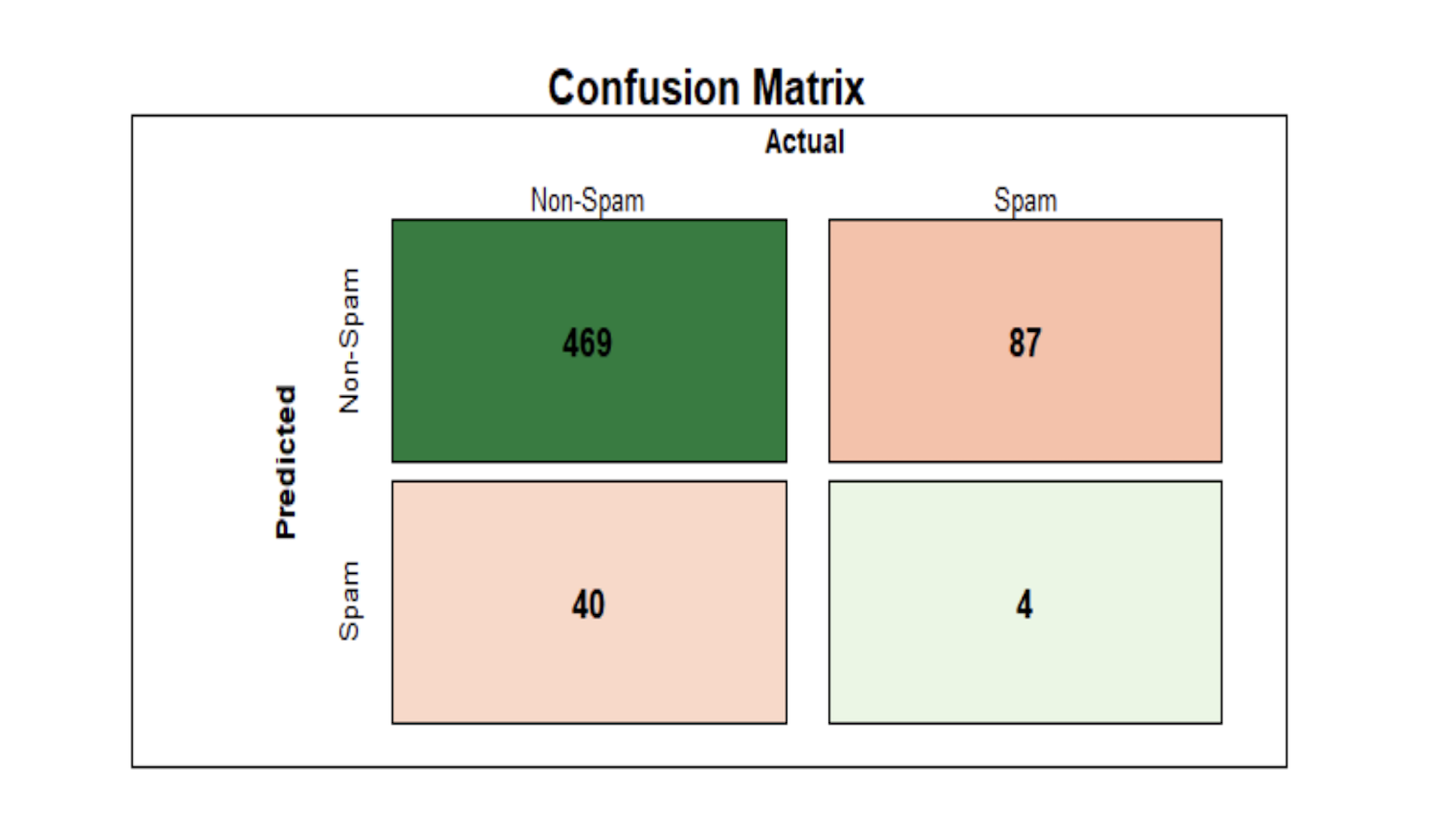
Used five classification methods to identify spam emails from non-spam through word frequency.
Learn more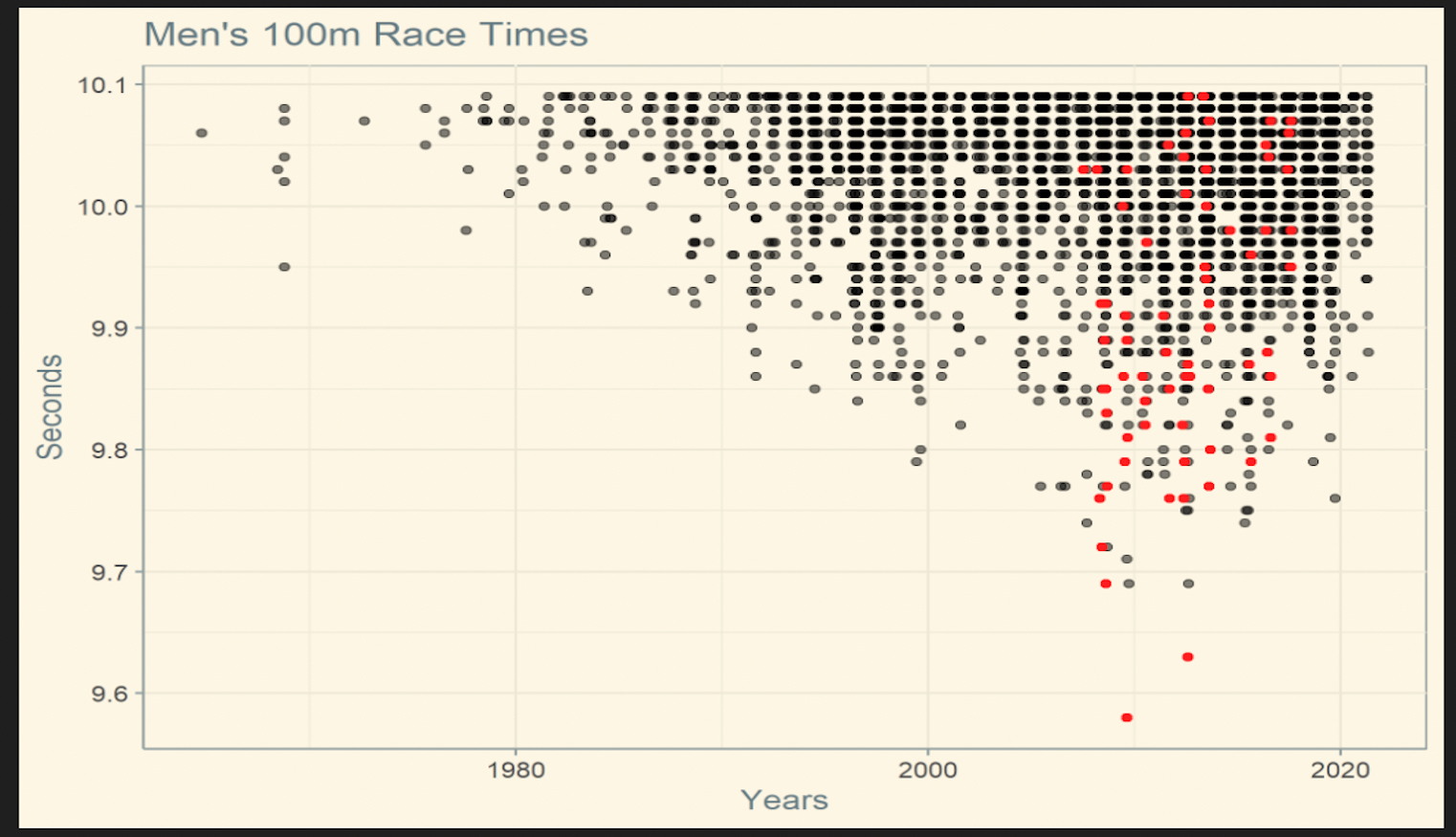
Webscraped, cleaned, and analyzed data from a Wikipedia page using rvest, RegEx, and ggplot2.
Learn more